AWS Lambda Performance and Cost Optimization
Following are key factors affecting the performance of serverless applications.
- Cold starts
- Memory and profiling
- Architecture and best practices
How does lambda work under the hood?

AWS Lambda function powered by Graviton2 provides up to 34% better performance and 20% lower cost over x86 based lambda.
AWS Graviton2 processor which contains 64-bit Arm Neoverse cores optimized for cloud-native applications.
Lambda function can be deployed with container image or .zip file to run on x86 or ARM-based processor.

Points to Consider before migrating an existing application from x86 to ARM processor.
- Interpreted and compiled byte code languages can run without modifications.
- Complied languages need to be recompiled for arm64
- Lambda container images need to be rebuilt for Arm
- AWS tools and SDKs support Graviton2 transparently.
Anatomy of a Lambda function:
- Handler() function →Function to be run upon invocation
- Event Object → Data sent during lambda function invocation
- Context Object → Methods are available to interact with the runtime and execution environment.
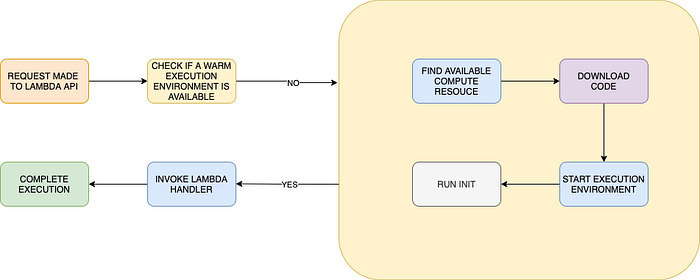
Function life cycle-worker host:
Full Cold Start: Steps performed when lambda runs the first time
- Downloads Code
- Starts Execution Environment
- Intensate Run Time
- Run Handler Code
Warm Start: Second lambda request received while the first request in progress
- Run Handler code
AWS Lambda function contains two types of optimizations.
- AWS Optimization → Downloads Code, Starts Execution Environment
- Developer Optimization → Intensate Run Time, Run Handler Code
Measuring performance of Lambda Function:
AWS X-ray will help to measure the performance of the Lambda Functions.
Type: AWS::Serverless::Function
Properties:
FunctionName: !Ref LambdaFunctionName
CodeUri:
Bucket: !Ref BucketName
Key: !Ref LambdaZipName
Handler: request_handler.lambda_handler
Runtime: python3.8
MemorySize: 320
Tracing: ActiveUsing SDK at the code level will help to add custom annotations and metadata
from aws_xray_sdk.core import xray_recorder@xray_recorder.capture("upload_to_s3_bucket:")
def upload_to_s3_bucket(data_feed: str):
pass
Three areas of performance:
- Latency
- Throughput
- Cost
Cold Starts:
Function life Cycle
Cold Start → Execution Environment
Facts:
- Effects < 1% prod env
- Varies from < 100ms to >1s
Considerations:
- Pinging functions to keep warm is limited
- Targeting warm environments are difficult
Cold start causes:
- Environments reaped
- Failure in underlying resources
- Rebalancing across AZs
- Updating code/config flushes
- Scaling up
Cold starts → Execution environments are influenced by the following factors from the AWS side.
- Memory allocation
- Size of function package
- How often is a function called
- Internal algorithms
Cold starts → Static initialization(Developer responsibility)
- Code run before handler
- Initialization of objects and connections
- New Execution environment running the first time
- Scaling up
Cold starts are influenced by the size of the function package, amount of code, and initialization work.
Developer responsibility for optimization of static cold starts.
Code Optimization:
- Trim SDKs
- Reuse connections
- Don’t load if not used
- Lazily load variables
Provisioned Concurrency:
If using a large library is mandatory use provisioned concurrency to avoid cold starts due to code size. Provision concurrency works by pre-creating the execution environment and running the INIT code.
Following are use cases for provisioned concurrency:
- Latency Sensitive and interactive workloads
- Improved consistency across the long tail of performance across P95, P99, and P100 levels
- Minimal change to code
- Integrated with AWS Autoscaling
- Adds a cost factor for per concurrency provisioned but lower duration cost per invocation. This could save money when heavily used
Function life cycle: Provisioned Concurrency Start
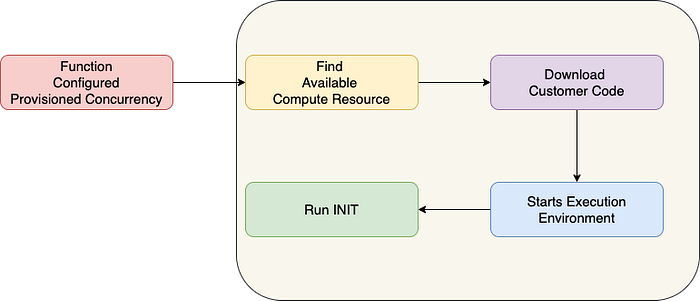
API Call to Lambda Function during provisioned concurrency start.
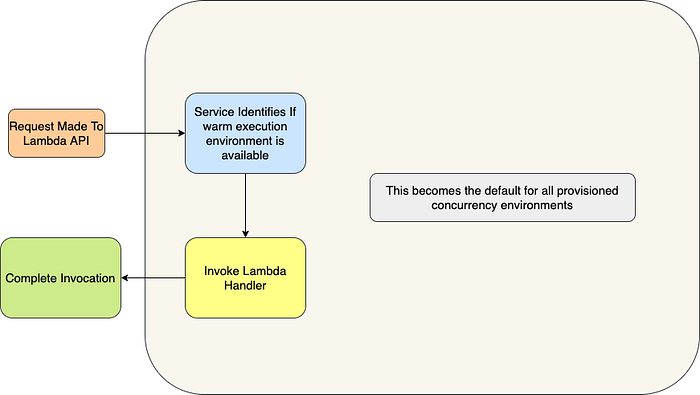
Provisioned Concurrency: Things to know
- Reduces start time to < 100 ms
- Can’t be configured for $LATEST. Use versions/aliases
- Provisioning ramp up of 500 per minute
- No changes to function handler code performance
- Requests above-provisioned concurrency follow on-demand lambda limits and behavior for cold-starts, bursting, and performance
- Overall account concurrency per region limit still applies
- Wider support for CloudFormation, Terraform, Serverless Framework ..etc
Things to know on the AWS side for provisioned concurrency:
- AWS provisions more than the requested limit
- Environment reap still applies
- There is Less CPU burst than on-demand during init
Provisioned Concurrency: Application Auto Scaling:
Autoscaling is used for scenarios in which the required capacity limit is not known clearly. It can be done using a min/max setting or alarm-based value.
ScalableTarget:
Type: AWS::ApplicationAutoScaling::ScalableTarget
Properties:
MaxCapacity: 100
MinCapacity: 1
ResourceId: !Sub function:${logicalName}:Live
RoleARN: !Join
- ':'
- - 'arn:aws:iam:'
- !Ref 'AWS::AccountId'
- role/aws-service-role/lambda.application-autoscaling.amazonaws.com/AWSServiceRoleForApplicationAutoScaling_LambdaConcurrency
ServiceNamespace: lambda
ScalableDimension: lambda:function:ProvisionedConcurrency
DependsOn: FunctionAliasLiveMemory Usage and Profiling:
Lambda CPU performance varied by memory allocation. An increase in memory will increase the CPU performance. If Lambda code is CPU and Network-intensive then allocating more memory will increase the performance of lambda dramatically.
CPU-bound function example:
Compute 1,000 times all primary ≤ 1M
128MB. 11.722 sec. $0.024628
256MB. 6.678 sec. $0.028035
512MB. 3.194 sec. $0.026830
1024MB. 1.465 sec $0.024638
Due to Lambda billing being on GB sec fine-tuning lambda to more memory is cheaper as overall execution time is less.
AWS Lambda Power Tuning: Open source tool helps to fine-tune lambda with memory vs performance vs cost.
Git repo: https://github.com/alexcasalboni/aws-lambda-power-tuning
Features:
- Data-driven cost and performance optimization
- Available from Serverless Repository
- Easy to integrate with CI/CD
- Compares two functions
{
"lambdaARN": "your-lambda-function-arn",
"powerValues": [128, 256, 512, 1024, 2048, 3008], or all
"num": 10,
"payload": "{}",
"parallelInvocation": true,
"strategy": "cost|speed|balanced",
"balancedWeight": 0.5 (0 refers spee strategy 1 refers cost strategy)
}{
"lambdaARN": "your-lambda-function-arn",
"powerValues": [128, 256, 512, 1024, 2048, 3008], or all
"num": 10,
"payload": "{}",
"parallelInvocation": true,
"autoOptimize": true
"autoOptimizeAliases": "Live"}
Using power tools we can compare performance vs cost vs speed of X86 and Arm/Graviton2 processors.
Architecture and best practices:
Optimization Best Practices:
- Avoid monolithic functions(Reduces deployment package size. Micro/Nano services)
- Minify/uglify production code
- Optimize dependencies
- Lazy initialization of shared libs/objects(Helps if multiple functions per file)
Optimized dependency usage(Node.js SDK & X-Ray):
//const AWS = require(‘aws-sdk’)const DynamoDB = require(‘aws-sdk/clients/dynamodb’) //125ms faster
X-ray usage
//const AWSXray = require(‘aws-xray-sdk’)const AWSXray = require(‘aws-xray-sdk-core’) //5ms faster
Lazy initialization example(Python and Boto3):
import boto3s3_client = Noneddb_client = Nonedef get_objects(event, context): if not s3_client:
s3_client = boto3.client(“s3”)# business logicdef get_items(event, context):if not ddb_clinet:ddb_client = boto3.client(“dynamodb”)# business logic
Note: Not a great option if we are using provisioned concurrency
Amazon RDS Proxy:
Fully managed highly available database proxy for Amazon RDS. Pools and shares connections to make applications more scalable, more resilient to database failures, and more secure.
Optimization best practices(performance/cost):
- Externalize Orchestration → Avoid idle/sleep- Delegate to a step function
- Fine-tune across resources allocation → Don’t guess estimate function memory
- Transform, not transport → Minimize data transfer(S3 select, advanced filtering,)
- Lambda Destinations → Simplified chaining(async) and DLQ
- Discard uninterested events asap → Trigger config(S3 prefix, SNS filter)
- Keep in mind that retry policies → Very powerful but not free
Reusing Connection with Keep-Alive:
- For functions using HTTPS requests
- Use in SDK with environment variables
- Or Keep-Alive property in function code
- Can reduce typical Dynamodb operation from 30ms to 10ms
- Available in most run time SDKs
Service Integration:
Service integration is common in modern application development.
- Adding services increases latency mainly a synchronous concern. Example service invokes lambda and Lambda calls another service.
- Use Asynchronous rather than synchronous if possible
- Use VTL where appropriate
- Use Step Function Direct SDK feature
- Use Lambda to transform don’t transport data
- Avoid lambda calling lambda
Lambda Invocation Model:
Lambda has 3 types of invocation models
- Synchronous(request/response)
- Asynchronous(event)
- Event Source Mapping(stream/queue poller)
Comparing sync vs async lambda services:
Lambda Service A → Lambda Service B
Synchronous:
- Caller is waiting
- Waiting occurs cost
- Downstream slows down affects entries process
- Process change is complex
- Passes payload between steps
Lambda Service A → SQS → Lambda Service B
Asynchronous:
- The caller receives ack quickly
- Minimizes cost of waiting
- Queening separates fast and slow processes
- Process change is easy
- Passes transaction ids
Lambda Performance →Summary
Cold Starts:
- Cause of cold start
- VPC improvements
- Provisioned concurrency
Memory and Profiling:
- Memory is the power of lambda
- AWS Lambda power tuning
- Trade-off cost and speed
Architecture and Optimization:
- Best Practices
- RDS Proxy
- Async and Service Integration
Stackademic
Thank you for reading until the end. Before you go:
- Please consider clapping and following the writer! 👏
- Follow us on Twitter(X), LinkedIn, and YouTube.
- Visit Stackademic.com to find out more about how we are democratizing free programming education around the world.

